Stable Diffusion 是一种文本到图像(Text-to-Image)的模型。给它一个文字提示,它返回一张与之匹配的 AI 图片。
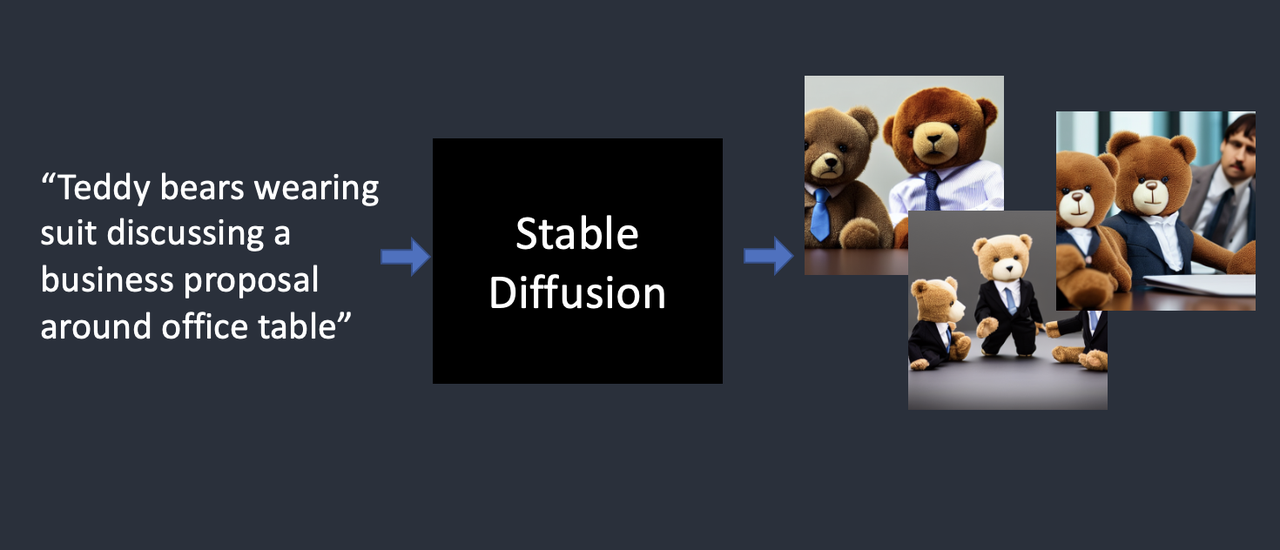
Stable Diffusion 属于一种称为扩散模型(Diffusion Model)的深度学习模型。
扩散模型 Diffusion Model
扩散模型在训练过程中,通过前向扩散(Forward Diffusion)将照片变成噪声,就像是一滴墨水滴在水里,墨水在水中扩散的效果。最终,你无法判断原始图像是什么。

如果我们逆转这一过程,从噪声开始,反向扩散恢复原始的图像。这就是 Diffusion Model 的基本思想。
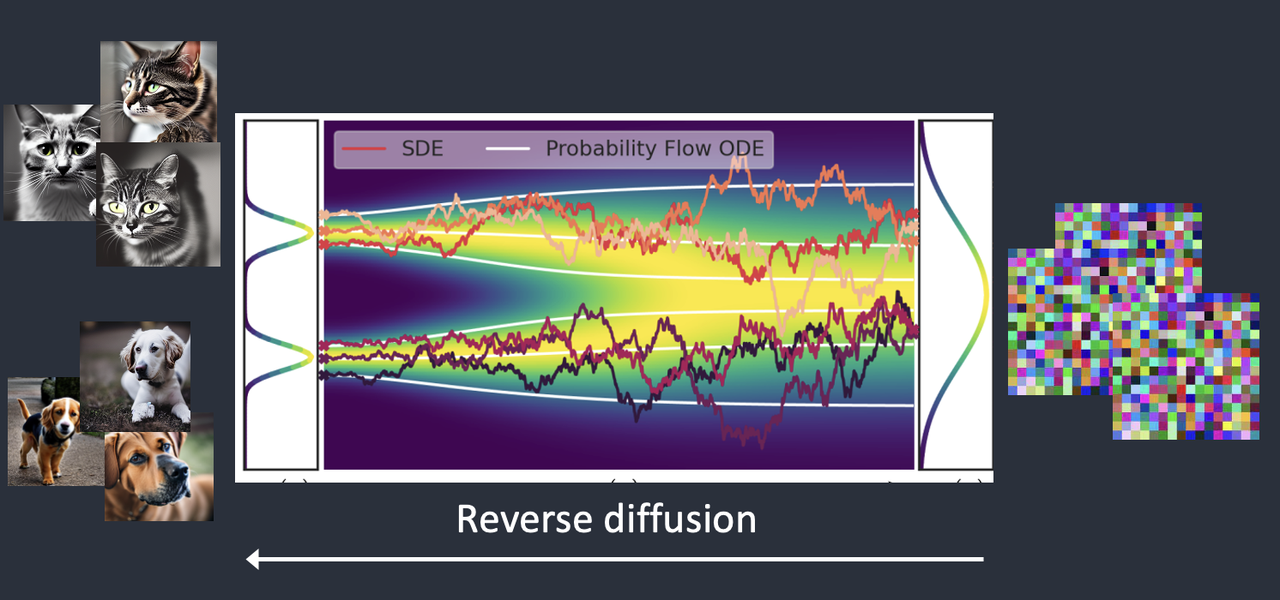
但是,价值百万美元的问题是:“如何才能做到这一点?”
加噪过程
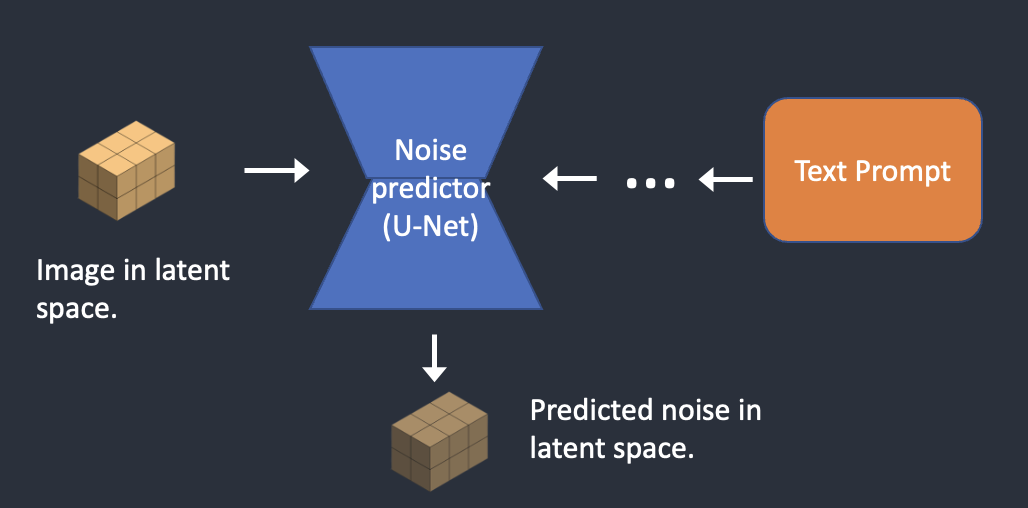
为了反转扩散,我们需要知道图像中添加了多少噪声。答案是训练神经网络模型来预测添加的噪声。在 Stable Diffusion 中叫做噪声预测器(Noise Predictor),是一个 U-Net 模型。
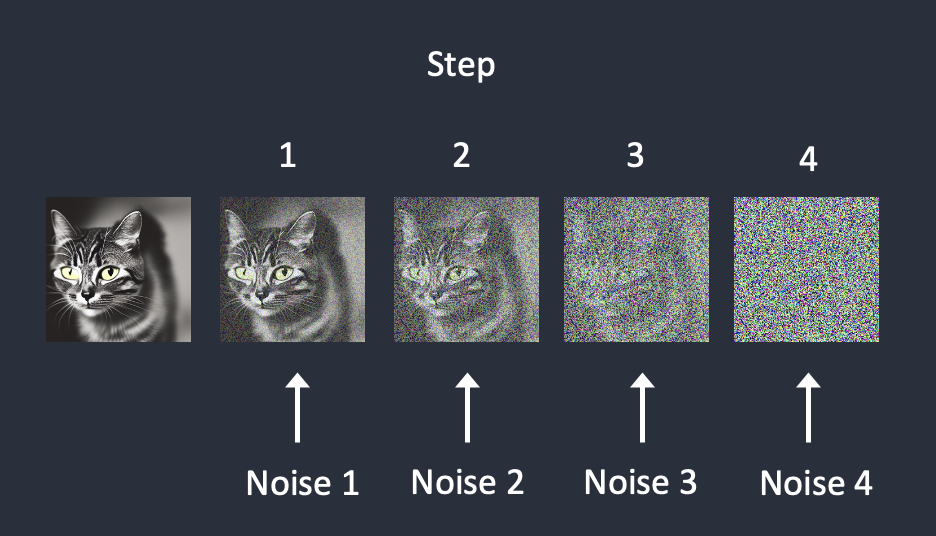
在每个步骤中依次添加噪声。噪声预测器估计每一步添加的总噪声。
去噪过程
去噪过程就是通过噪声预测器,首先生成一个完全随机的图像,减去估计的噪声。重复过程,得到最终的图像。
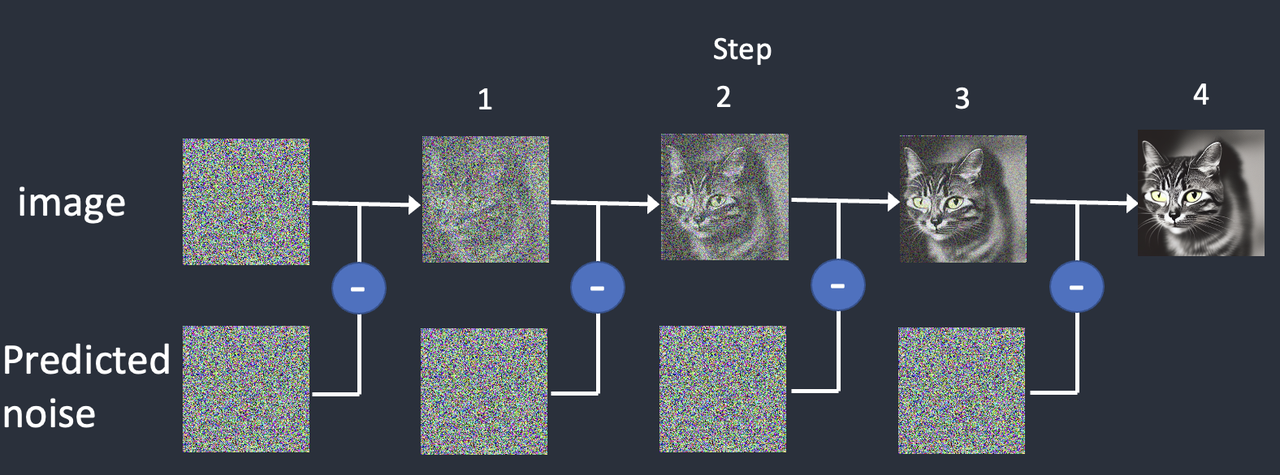
反向扩散的原理是连续从图像中减去预测的噪声
整个去噪过程是一个迭代过程,如果迭代步数太少,则图片可能还存在噪声。但是迭代步数太多,对图像的精细程度反而没有太多帮助。
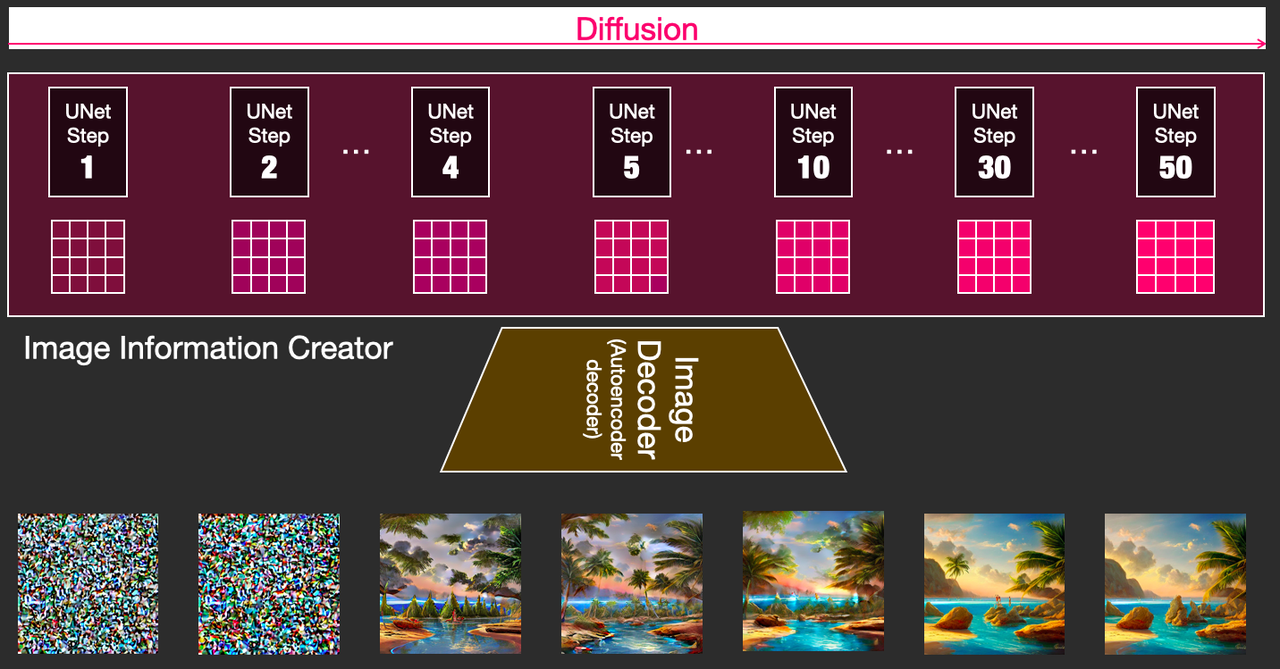
上面的扩散模型工作原理是在图像空间(Pixel space)进行的,图像空间是巨大的,计算速度非常慢。也意味着模型运行的速度非常慢。
潜在扩散模型 Latent Diffusion Model
Stable Diffusion 模型旨在解决速度问题,它是一种 Latent Diffusion 模型。不在高维图像空间中操作,而是首先把图像压缩到潜在空间(Latent Space)中。为了解释这个“潜”空间的概念,可用一张图来形象展示:
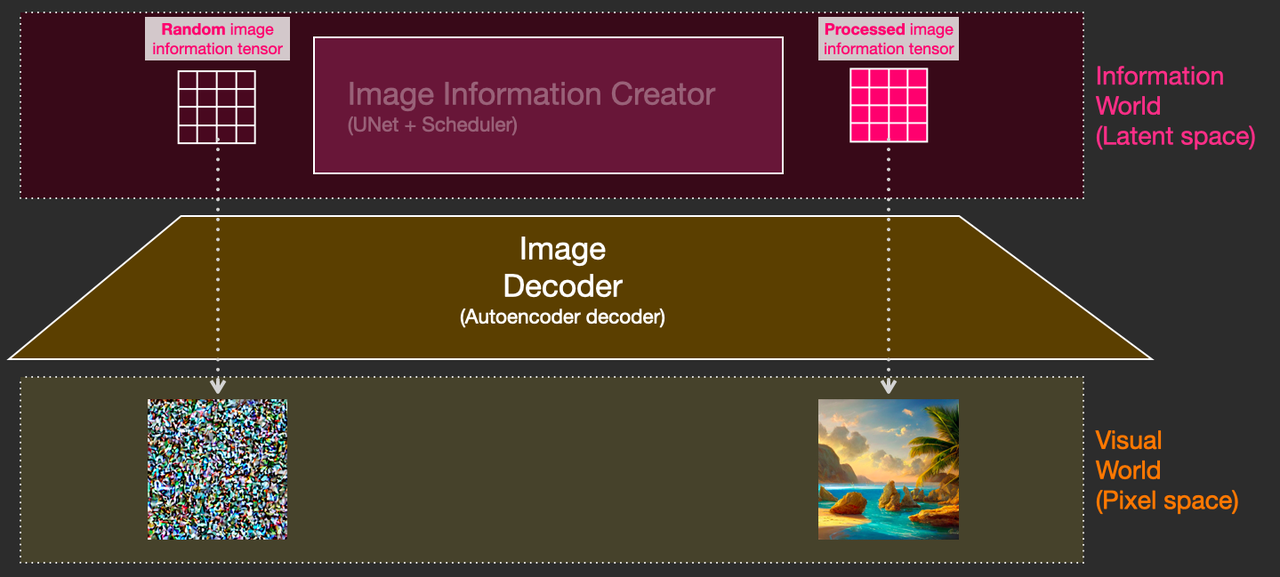
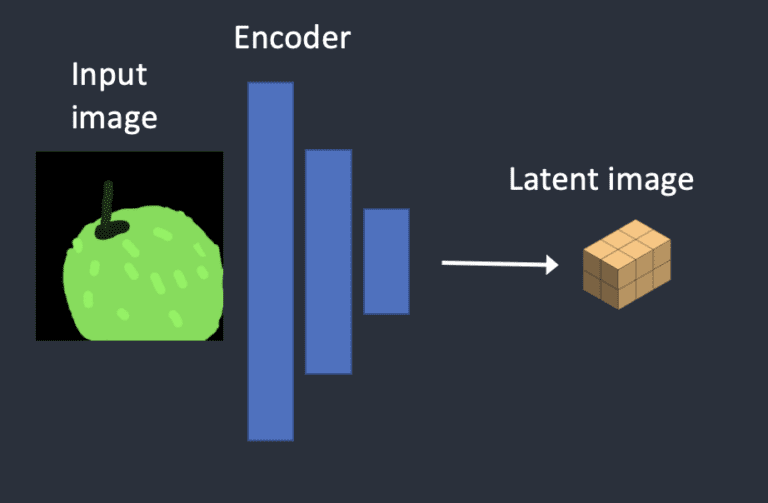
简单来说,为了减少计算。图像通过 VAE 进行编码,输出到潜空间。后续完成完成反向扩散之后,再通过 VAE 解码到图像空间。
变分自动解码器 Variational AutoEncoder
它是使用一种称为变分自动编码器(VAE)的技术来完成的。VAE 通过编码器将图像压缩为潜在空间的较低维,解码器再从潜在空间恢复图像。
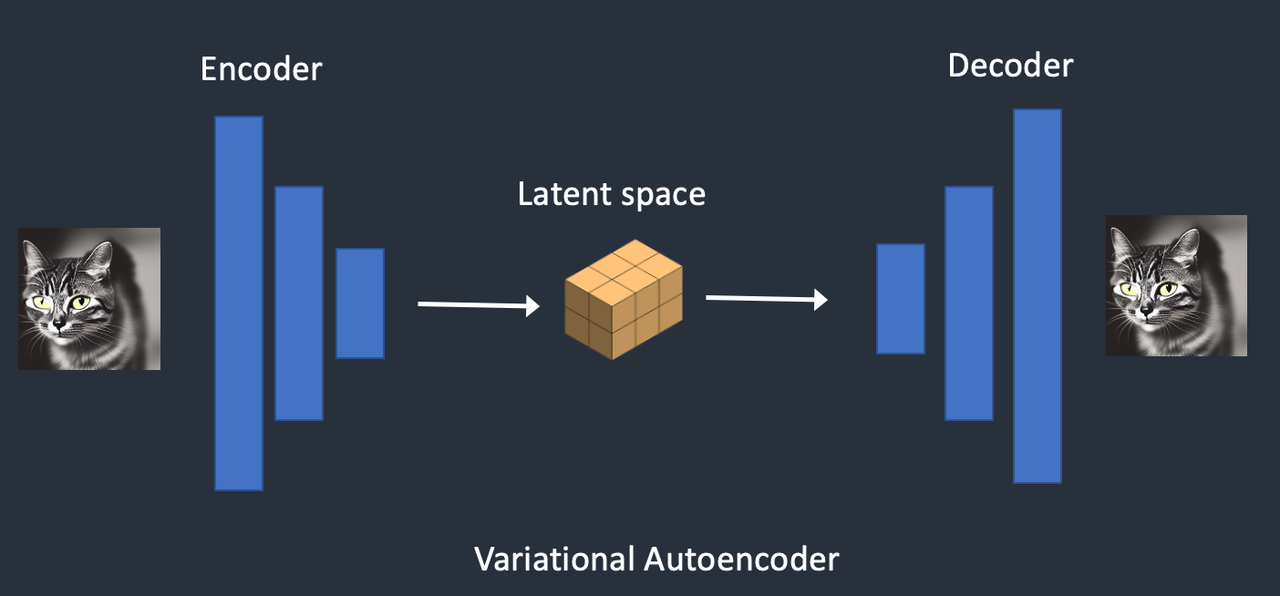
Stable Diffusion 模型的潜在空间为 4x64x64,比图像像素空间小 48 倍。我们谈到的所有前向和反向扩散实际上都是在潜在空间中完成的。
将图像压缩到潜空间会丢失信息,因为自动 VAE 无法恢复精细细节。在 Stable Diffusion V1 中,我们使用 .vae 后缀的文件来改善眼睛和面部,就是通过微调 VAE 解码器,使模型可以绘制更精细的细节。
调节 Conditioning
这里还有一个问题,就是文字 Prompt 从哪里进入图像。如果没有它,就没法控制最终我们获得的图像。Conditioning 的目的就是引导噪声预测器,以便预测的噪声在从图像中减去后能够为我们提供我们想要的结果。
文本调节 Text conditioning
文本调节,也就是 Text-to-Image。Tokenizer 首先将提示中的每个单词转换为一个称为标记的数字。然后,每个标记都会转换为 768 个值的向量,称为嵌入(Embedding)。嵌入随后由文本转换器进行处理,输出提供给 噪声探测器。
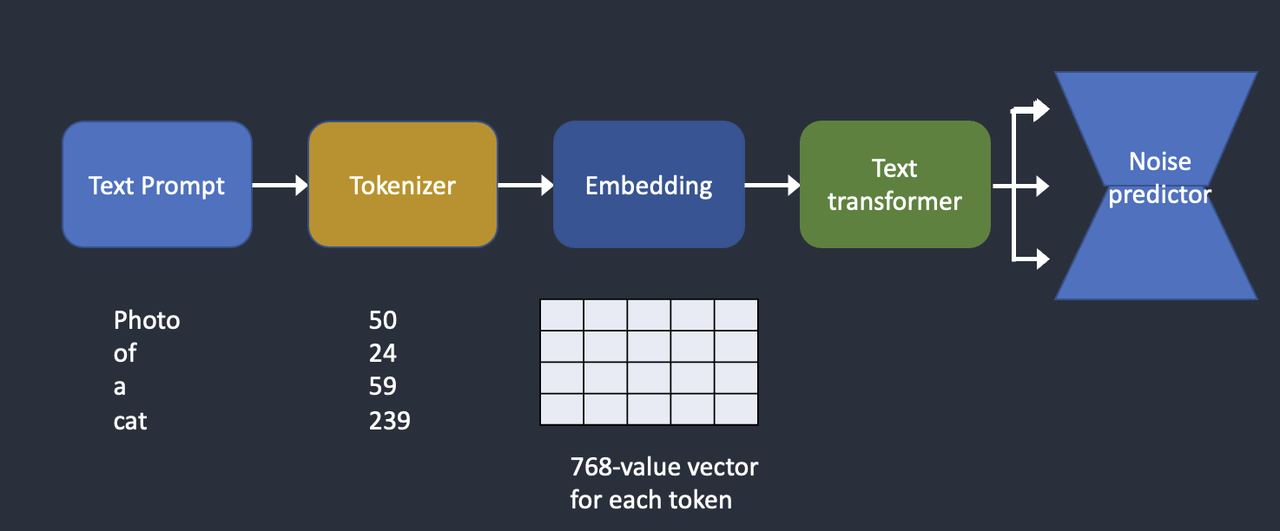
这一过程的简要介绍:
Tokenizer
文本 Prompt 首先由 CLIP Tokenizer 进行标记。标记(Tokenization)是计算机用来理解但是的方式。
CLIP 是 Open AI 开发的深度学习模型,Stable Diffusion V 使用的 CLIP 的 Tokenizer。
Tokenizer 是一个模型,所以只能对训练期间的看到的单词进行标记。例如,CLIP 模型中有 “dream” 和 “beach”,但没有“dreambeach”。Tokenization 会将“dreambeach”一词分解为两个标记 “dream” 和 “beach”。所以一个词并不总是意味着一个标记。
Stable Diffusion 模型仅限于在提示中使用 75 个标记。
嵌入 Embedding
Stable Diffusion v1 使用 Open AI 的 ViT-L/14 Clip 模型。嵌入是一个 768 值向量。每个标记都有自己独特的嵌入向量。嵌入由 CLIP 模型固定。
为什么我们需要嵌入?这是因为有些词彼此之间密切相关。例如,man、gentleman 和 Guy 的嵌入几乎相同,因为它们可以互换使用。莫奈、马奈和德加都以印象派风格作画,但方式不同,这些名称具有接近但并不相同的嵌入。
文本转换器 Text transforming
在输入噪声预测器之前,嵌入需要由文本转换器进一步处理。文本转换器就像一个用于调节的通用适配器。在这种情况下,它的输入是文本嵌入向量,但它也可以是其他东西,例如类标签、图像和深度图。变压器不仅进一步处理数据,而且提供了一种包含不同调节模式的机制。
文本转换器的输出通过 U-Net 被噪声控制器多次使用。U-Net 通过 Cross-attention mechanism 来使用它。
Cross-attention mechanism
Hypernetwork 就是劫持 cross-attention network 来微调 Stable Diffusion 模型的一种技术。LoRA 模型则是修改 cross-attention 模块的权重来改变风格。单独修改这个模块就可以微调 Stable Diffusion 模型。
其他调节方式
文本 Prompt 不是唯一调节 Stable Diffusion 扩散模型的唯一方法。深度图像也可以调节 depth-to-image 模型。ControlNet 使用检测到的轮廓、人体姿势来调节噪声探测器。
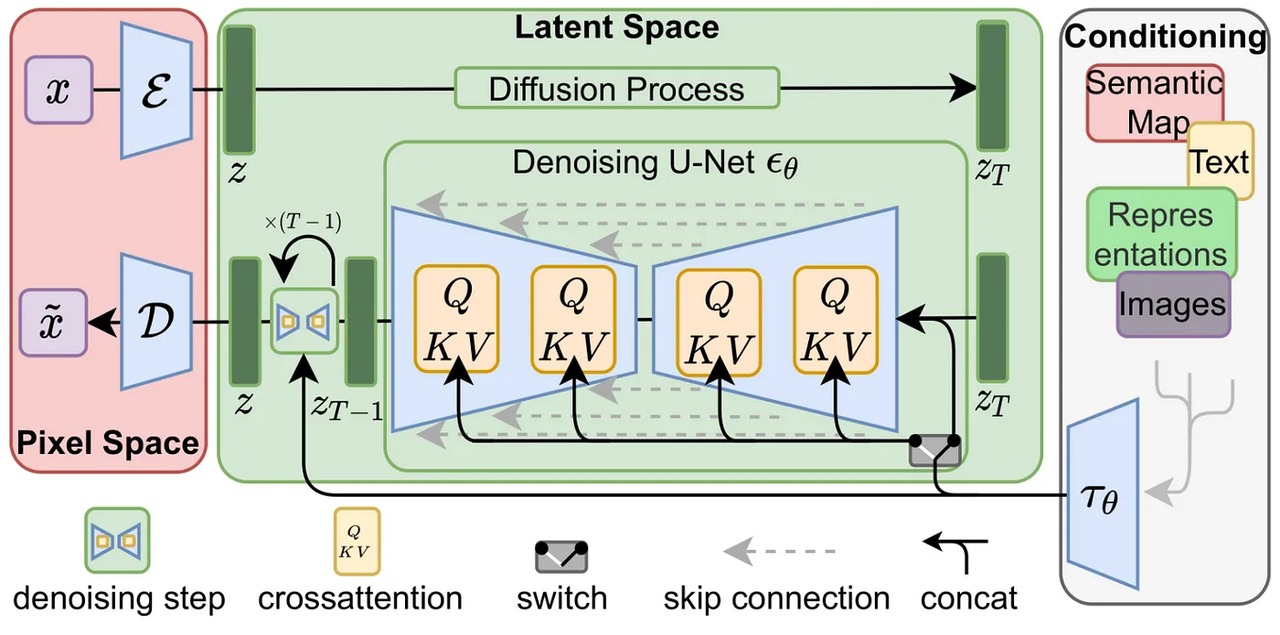
Stable Diffusion
LDM/Stable Diffusion 论文里的这张图很好地整体描述了上面的三个过程,分别是:
- 通过 VAE 将图像从图像空间转移到潜空间计算
- 通过调节手段引导 U-Net 模型,控制想要获得的图像
- U-Net 模型重复第二步进行迭代
- 潜在图像通过 VAE 解码器转移到图像空间
我们通过实际的文生图和图生图来了解背后的情况。
文生图 Text-to-image
文生图通过文本 Prompt,返回一张图片。大致的步骤如下:
步骤一:生成随机张量
Stable Diffusion 在潜在空间中生成随机张量。可以通过设置随机数生成器的种子来控制该张量。如果将种子设置为某个值,您将始终获得相同的随机张量。这是你在潜在空间中的图像。但目前这都是噪音
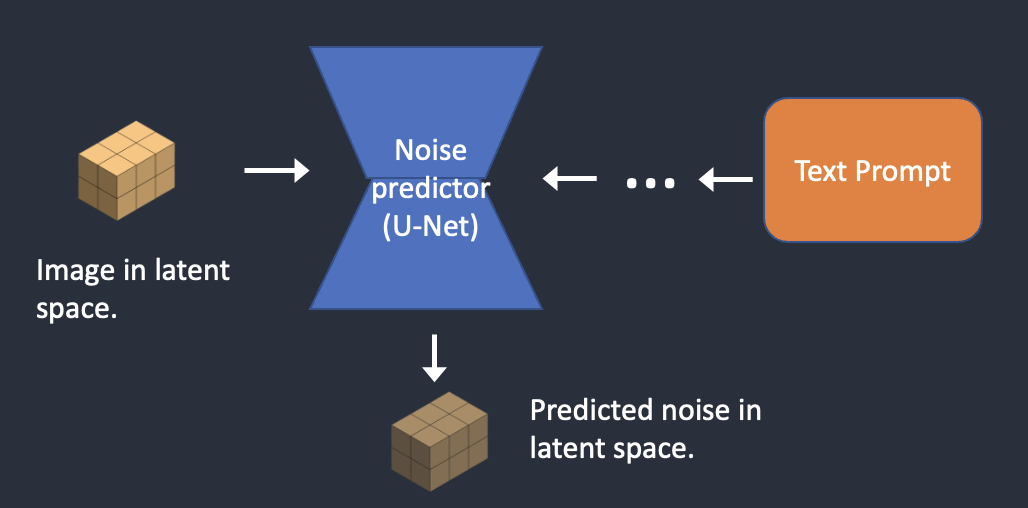
步骤二:调节噪声预测器
噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并在潜在空间(4x64x64 张量)中预测噪声。
步骤三:减去潜在噪声
从潜在图像中减去潜在噪声。这成为你新的潜在空间图像。
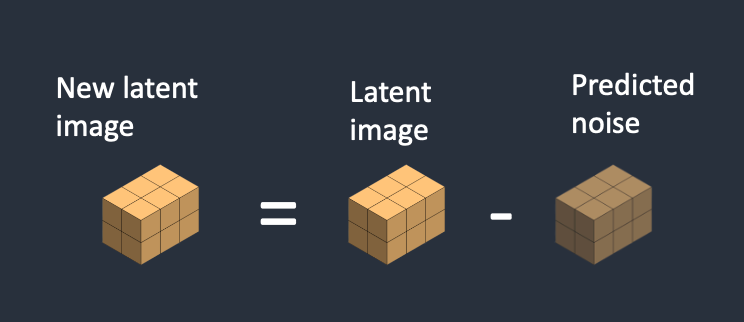
重复步骤 2 和 3 的采样步骤(Sampling Steps),例如20次。
步骤四:VAE 解码
最后,VAE的解码器将潜在图像转换回像素空间。这是运行稳定扩散后获得的图像。
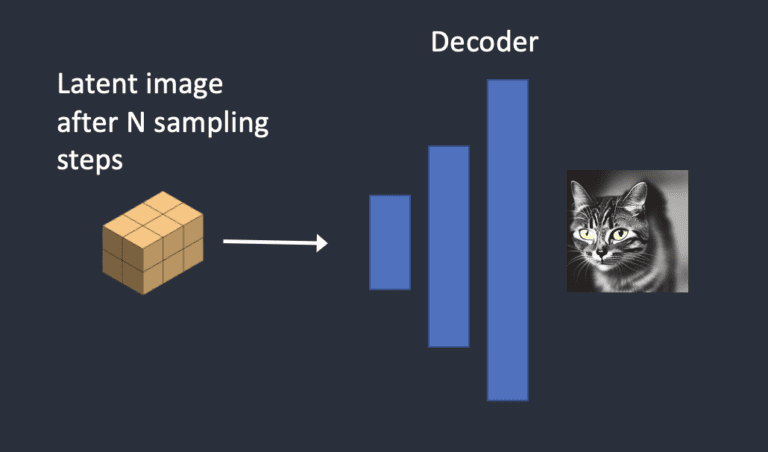
以下是图像在每个采样步骤中的演变方式:

图生图 Image-to-Image
图生图首次在 SDEdit 中提出,SDEdit 可应用于任何扩散模型。输入的图像和文本 Prompt 作为图像到图像的输入提供,生成的图像将受到两者的影响。
这个过程的大致步骤如下:
步骤一:输入的图像被编码到潜在空间
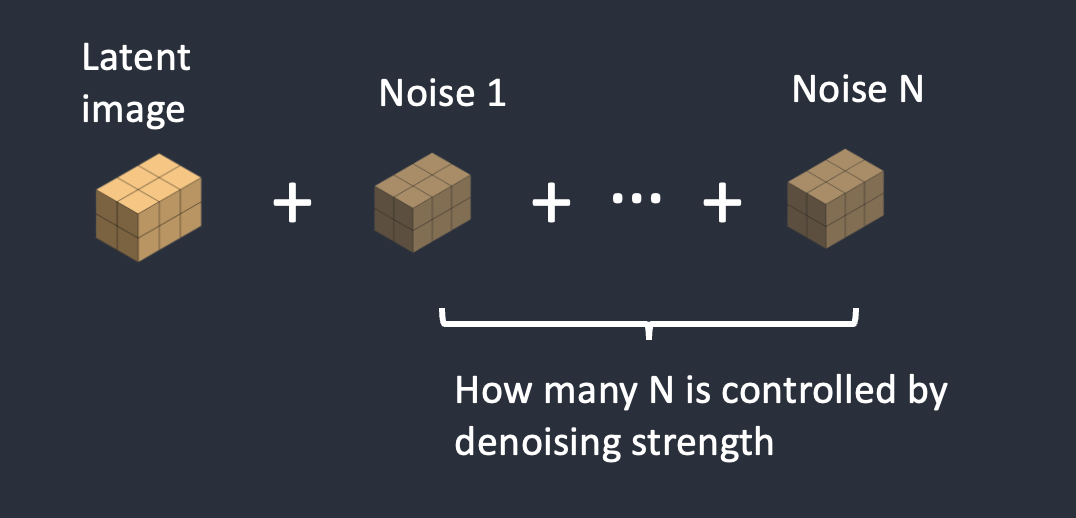
步骤二:将噪声添加到潜在图像中
去噪强度(Denoising Strength)控制添加的噪声量。如果为 0,则不添加噪声。如果为 1,则添加最大量的噪声,使第一步生成的潜在图像变成完全随机的张量。
步骤三:调节噪声预测器
噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并预测潜在空间(4x64x64 张量)中的噪声。
步骤四:减去潜在噪声
从潜在图像中减去潜在噪声。这成为你新的潜在噪声。重复步骤 3 和步骤 4 N 次。N 称为采样步数。
步骤五:VAE 解码
VAE的解码器将潜在图像转换回像素空间。
Reference
本章节部分内容来源 https://stable-diffusion-art.com/how-stable-diffusion-work/ 和 https://stable-diffusion-art.com/how-stable-diffusion-work/