X 公布了其推荐算法,并在 Twitter’s Recommendation Algorithm 这篇文章中进行了介绍。
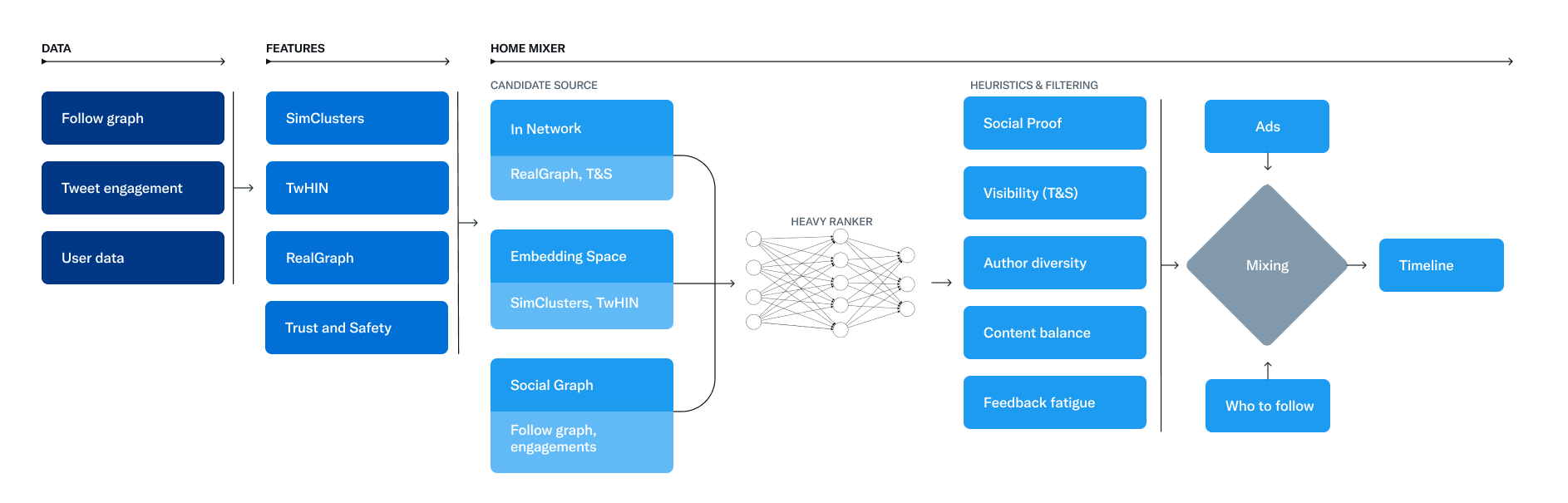
包含了推荐算法常见的三个流程:
- 召回:从不同的候选集获取最合适的推文 - Candidate Sourcing
- 排序:使用机器学习算法进行排序 - Ranking
- 重排:过滤掉屏蔽的用户推文、NSFW 和已经看过的内容 - Heuristics and filters
Candidate Sources 过程
X 会从 In-Network (你关注的用户) 和 Out-of-Network (你没有关注的用户) 提取最好的 1500 条推文。如今,For You 时间线的就包含 50% 和 In-Network 和 50% Out-of-Network 的推文。
In-Network Source
使用 Logistic Regression Model,根据你关注的用户的最新推文,根据推文的相关性对推文进行排序。
对推文进行排序最重要的部分是 Real Graph,用来预测两个用户之间互动可能性的模型。
Out-of-Network Sources
X 是如何在网络外查找推文的策略主要依赖两个:
- Social Graph
通过分析您关注的人或具有相似兴趣的人的参与度来估计您认为相关的内容。
- 我关注的人最近接触了哪些推文
- 谁喜欢和我类似的推文,他们最近还喜欢什么
- Embedding Spaces
这个主要是为了回答:哪些推文和用户与我的兴趣相似。
Ranking 过程
Ranking 过程将召回的 1500 条帖子,通过一个 ~48M 参数的神经网络实现。这个排名机制考虑了数千个标签,输出 10 个标签进行打分。
重排
- Visibility Filtering - 根据推文的内容和你的偏好过滤掉推文
- Author Diversity - 避免单个作者连续发布太多推文
- Content Balance - 确保我们在网络内和网络外推文之间实现公平的平衡
- Feedback-based Fatigue - 如果观看者提供了负面反馈,则降低某些推文的分数
下面是一些策略
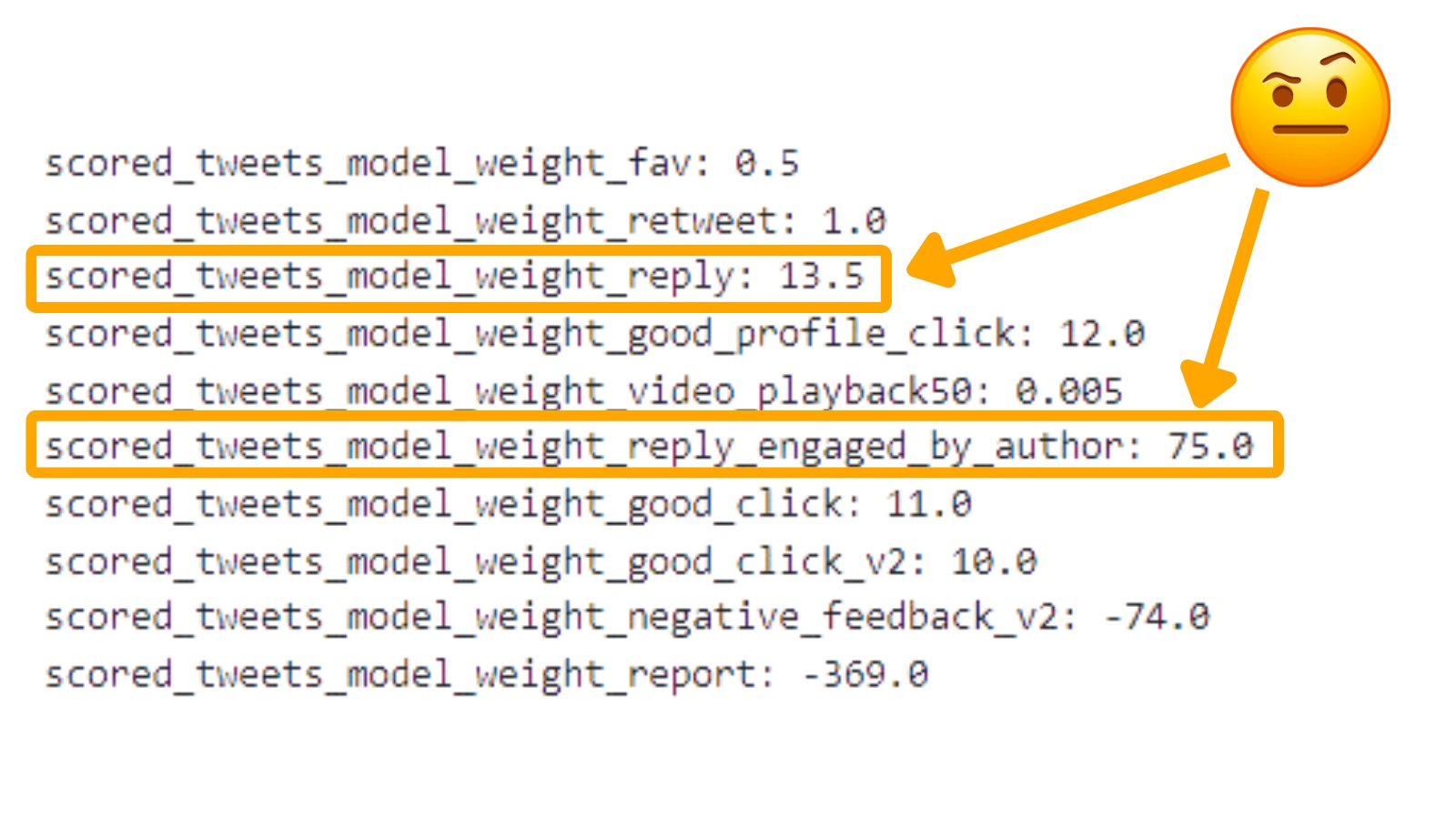
X Premium 存在加成
回复加成
- 回复自己帖子下的评论
- 评论或回复别人的帖子
给帖子添加视频和图片
来源:https://hypefury.com/blog/en/how-the-x-twitter-algorithm-works/